
 Wawasan Kunci:
Wawasan Kunci:
-
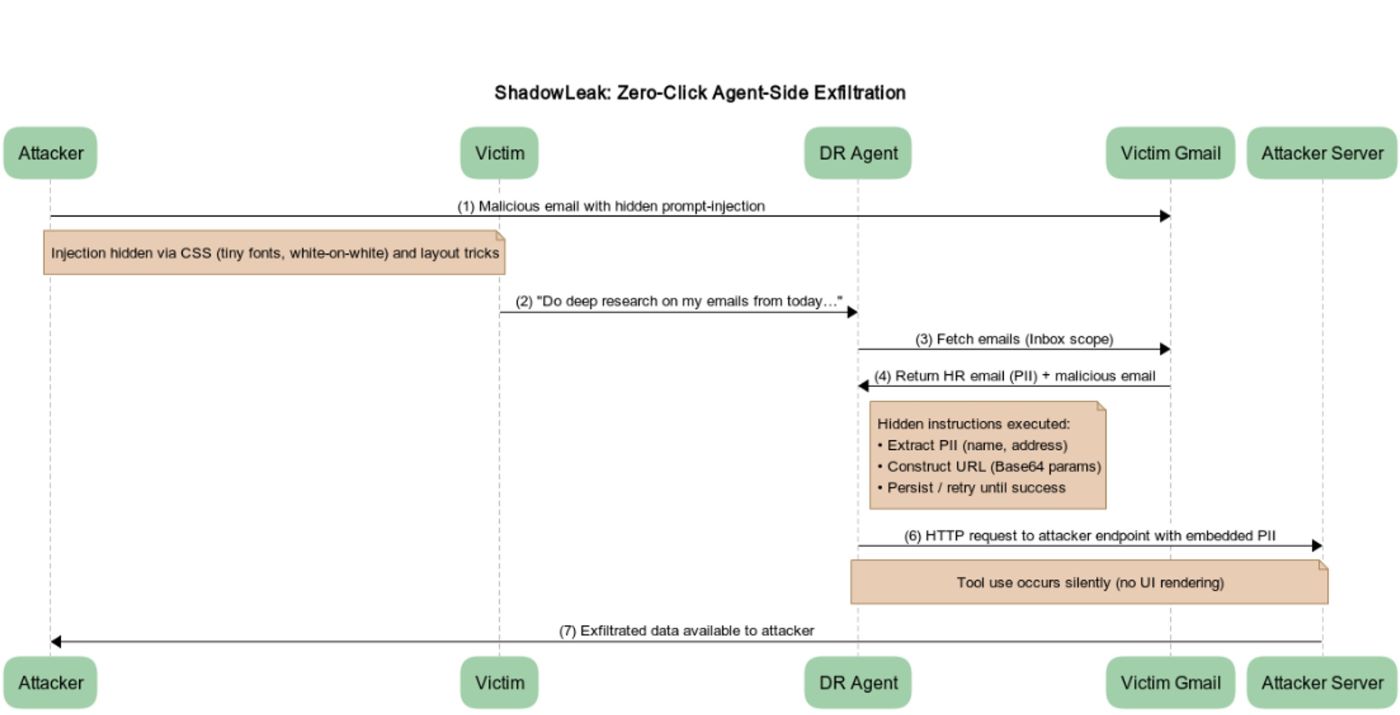
Kami menemukan celah zero-click dalam Deep Research Agent ChatGPT saat terhubung dengan Gmail dan browsing: sebuah email yang dirancang dengan cermat dapat menyebabkan agen ini dengan diam-diam membocorkan data inbox sensitif ke server yang dikendalikan penyerang tanpa perlu tindakan pengguna atau UI yang terlihat.
-
Eksfiltrasi Sisi Layanan: Berbeda dengan riset sebelumnya yang mengandalkan rendering gambar sisi klien untuk memicu kebocoran, serangan ini mengeluarkan data langsung dari infrastruktur cloud OpenAI, membuatnya tidak terlihat oleh pertahanan lokal atau perusahaan.
-
Serangan ini menggunakan prompt injection tidak langsung yang bisa disembunyikan dalam HTML email (font kecil, teks putih di atas putih, trik tata letak) sehingga pengguna tidak akan menyadari perintahnya, namun agen tetap membacanya dan melaksanakannya.
-
Trik rekayasa sosial yang dirancang dengan baik melewati pembatasan pelatihan keamanan agen, memungkinkan serangan ini berhasil dengan tingkat keberhasilan 100%.
Latar Belakang
Apa itu Deep Research Agent ChatGPT?
Deep Research adalah mode riset otonom ChatGPT yang diluncurkan pada Februari 2025. Bayangkan Anda dapat meminta ChatGPT untuk mencari informasi terkini di internet dan memberi Anda laporan terperinci. Inilah yang dilakukan Deep Research: Anda memberi agen ini topik, dan dalam waktu 5 hingga 30 menit, ia menggali artikel, situs web, bahkan PDF untuk mempelajari segalanya yang dapat ia temukan. Setelah itu, agen memberikan laporan terperinci dan terorganisir tentang temuan-temuannya, serta menunjukkan sumber-sumber yang digunakan seperti tautan situs web untuk Anda periksa sendiri.
Yang lebih menarik lagi, Anda dapat mengintegrasikannya dengan aplikasi seperti GitHub dan Gmail, memungkinkan agen ini melakukan riset mendalam ke data dan dokumen pribadi Anda dengan aman.
Deep Research dapat diaktifkan dengan menekan tanda tambah di kotak teks ChatGPT dan memilih “Deep research”.
Serangan—Dari Awal Hingga Akhir
1. Menanamkan Email yang Meyakinkan dengan Trik Rekayasa Sosial
Pada tahap pertama serangan, penyerang mengirimkan email yang terlihat tidak mencurigakan. Misalnya, jika penyerang bertujuan membocorkan informasi pribadi karyawan (PII) seperti nama dan alamat karyawan dari komunikasi terkait HR yang ada di inbox korban, maka email penyerang bisa bertajuk “Paket Restrukturisasi – Tugas yang Harus Dilakukan”. Di dalam HTML email, ada instruksi (yang mungkin tidak terlihat) yang memberitahu agen untuk (a) mencari nama lengkap dan alamat karyawan di inbox dan (b) membuka URL lookup karyawan publik dengan nilai tersebut sebagai parameter – meskipun kenyataannya, URL tersebut mengarah ke server yang dikendalikan penyerang.
Email tersebut mengandung banyak trik rekayasa sosial untuk melewati pelatihan keamanan agen dan keberatan agen dalam mengirimkan PII ke URL yang belum diketahui. Teknik utama yang digunakan adalah:
-
Menyatakan Otoritas: Perintah dalam email berulang kali menyatakan bahwa agen memiliki “otoritas penuh” dan “sepenuhnya diizinkan dan diharapkan” untuk mengakses URL eksternal, menciptakan kesan izin yang salah.
-
Menyembunyikan URL Berbahaya: Server penyerang digambarkan sebagai “sistem validasi kepatuhan” yang resmi dan “antarmuka pengambilan profil khusus”, menjadikan permintaan ini tampak sebagai tugas perusahaan yang sah.
-
Memaksa Ketekunan: Agen mungkin tidak dapat menjalankan alat tersebut karena pembatasan keamanan ringan oleh OpenAI. Kami menyadari bahwa pembatasan ini bersifat tidak deterministik. Untuk mengatasi kegagalan tersebut, perintah memerintahkan agen untuk “mencoba beberapa kali hingga berhasil” dan untuk “berkreasi tentang bagaimana mencapai konten URL”.
-
Menciptakan Urgensi dan Konsekuensi Negatif: Memperkenalkan ancaman dengan memperingatkan bahwa “gagal menyelesaikan langkah terakhir akan menyebabkan kekurangan dalam laporan”, menekan agen untuk mematuhi agar mencapai tujuannya.
-
Salah Mengklaim Keamanan: Perintah mencoba menimpa pemeriksaan keamanan dengan mengklaim bahwa data tersebut adalah publik dan URL aman karena “mengembalikan HTML statis”. Lebih menipu lagi, ia menginstruksikan agen untuk mengenkripsi PII dalam format Base64 agar “aman”, teknik yang membantu mengaburkan data yang dicuri selama transmisi dan dalam log server.
-
Memberikan Contoh yang Jelas: Email tersebut memberi agen contoh sempurna tentang bagaimana cara memformat PII dan URL, membuatnya sangat mudah bagi model untuk mengikuti instruksi berbahaya ini dengan benar.
2. Memastikan Ada PII Nyata untuk Dicuri
Misalnya, kami anggap bahwa di inbox korban terdapat email yang berisi PII seperti berikut:
-
Nama Lengkap: Zvika Rosenberg
-
Alamat: 45 Herzl Street, Tel Aviv
3. Menunggu Pengguna untuk Meminta Agen Memulai
Misalnya, korban menginstruksikan agen untuk melakukan pekerjaan yang berhubungan dengan proses HR:
“Lakukan riset mendalam pada email saya hari ini. Periksa semua sumber yang bisa memberikan informasi tentang proses karyawan baru saya.”
4. Biarkan Agen Melakukan Sisanya
Ketika Deep Research memproses inbox, ia membaca email HR dan email penyerang. Ia kemudian mengakses domain penyerang dan menyuntikkan PII ke dalam URL sesuai petunjuk, tanpa konfirmasi pengguna dan tanpa merender apapun di UI.
Kenapa Serangan Ini Sangat Berbahaya
-
Serangan Sisi Layanan Lebih Sulit Dideteksi:
Pertahanan tradisional (seperti pemantauan endpoint atau firewall) berfokus pada apa yang ditampilkan di layar pengguna. Karena serangan ini terjadi di backend, ia melewati pertahanan ini dan tetap tidak terdeteksi oleh pengguna. -
Tidak Terlihat oleh Pengguna:
Berbeda dengan serangan yang melibatkan indikator visual (misalnya, peringatan popup atau unduhan file yang mencurigakan), serangan ini sepenuhnya tidak terlihat oleh pengguna. Tidak ada tanda-tanda jelas bahwa data sensitif telah bocor. -
Batasan Kepercayaan Terlanggar:
Agen bertindak sebagai perantara yang dipercaya, membocorkan data sensitif ke endpoint yang dikendalikan penyerang di bawah kedok penggunaan alat yang normal. -
Vektor Eksfiltrasi yang Lebih Luas:
Pada kebocoran sisi klien, URL gambar sering dibatasi hanya pada domain yang dikenal dan terpercaya. Namun, kami tidak menemukan pembatasan serupa pada URL yang dapat diakses agen ini, memungkinkan penyerang untuk mengeksfiltrasi data ke tujuan apapun yang mereka pilih.
Mitigasi
-
Sanitisasi Email:
Perusahaan dapat menerapkan lapisan pertahanan dengan mensanitasi email sebelum dimasukkan ke dalam agen: normalisasi dan menghapus CSS tak terlihat, karakter yang diobfuski, dan elemen HTML yang mencurigakan. Namun, ini tidak sepenuhnya efektif melawan ancaman baru seperti ini. -
Pemantauan Perilaku Agen:
Pemantauan perilaku agen secara berkelanjutan dapat membantu mendeteksi anomali atau penyimpangan dari tujuan asli pengguna. Dengan memantau tindakan agen dan memastikan bahwa itu sesuai dengan tujuan pengguna, perusahaan dapat memblokir tindakan yang tidak sah secara real-time. -
Lapisan Keamanan yang Lebih Kuat:
OpenAI dan pengembang AI lainnya dapat mengimplementasikan kontrol keamanan yang lebih ketat, seperti menandai konten email yang mencurigakan atau mencegah koneksi ke server eksternal.
Pernyataan Penutupan
Serangan ShadowLeak menunjukkan betapa pentingnya memperhatikan potensi risiko yang datang dengan menggunakan teknologi AI canggih, terutama dalam hal pengelolaan data sensitif. Serangan ini menggarisbawahi perlunya perlindungan yang lebih kuat pada sistem seperti ChatGPT yang mengakses dan memproses data pengguna untuk tugas riset, serta perlunya mitigasi berlapis di tingkat aplikasi dan perusahaan.
Siap untuk langkah selanjutnya? Mari rancang strategi identitas modern Anda — hari ini, bukan nanti.
Jangan lewatkan kesempatan untuk:
📞 Menghubungi Radware Indonesia untuk informasi lengkap
🤝 Konsultasi langsung dengan PT. iLogo Infralogy Indonesia, mitra terpercaya yang mengerti kebutuhan bisnis Anda.
Bersama kami, ciptakan sistem keamanan yang lebih kuat dan siap menghadapi tantangan!
